



二、计算机基础:
1,中央处理单元CPU:
CPU功能:程序控制,操作控制,时间控制,数据处理
CPU组成:运算器(数据加工、算数运算、逻辑运算),控制器(保证指令执行、处理异常事件),寄存器组(保存程序的中间结果),总线.
其中:
运算器包括:算术逻辑单元ALU(算术和逻辑运算)、累加寄存器AC(运算结果或源操作数存放)
数据缓冲寄存器DR(暂时存放内存的指令或者数据)、状态条件寄存器PSW(保存条件码或溢出标志)
控制器包括:指令寄存器IR(存指令)、程序计数器PC(存指令执行地址)、地址寄存器AR(CPU访问的内存地址)、指令译码器ID(指令操作码)
2,进制转换:
小数转二级制:2^-1=1/2^1=0.5 2^-2=1/2^2=0.25 2^-3=0.125 2^-4=0.0625
带符号位的的二级制数转化为十进制(最高位 0正 1负)除去最高位 1101=-5
3,数据的表示:
原码:最高位 0正 1负
[+0]原=1 000 [-0]原=0 000
例如:1010 =0*2^2+1*2^1+0*2^0=2-->-2
反码(原码最大的问题就在于一个数加上它的相反数不等于0,所以引用反码):正数=原码 负数=除符号位 按位取反
[+0]反=1 000 [-0]反=0 111
补码(计算机采用补码+-运算,将减法转换为加法):正数=原码 负数=反码+1或者2的机器字长次幂-负数的绝对值得到的差的原码
移码:补码符号位取反
浮点数表示:
N=(尾数)基数^阶码(指数) 12450=1.245X10^4
阶码(指数)--移码(范围) 尾数--补码(精度)
对阶时,小数向大数看起,尾数向右移动。
4,检验码:
奇偶检验码:数据位和检验位1的个数决定,所以产生不了全为0的代码(奇数个位出错能检测,偶数个出错不能检测(漏检))
CRC检验码:只能检错不能纠错
1,原始10110 G(x)=X^4+x+1---->10011
2,原始加上0000(因为多项式为4阶)--->101100000
3,101100000模2除法10011(同为0异为1)--->余数为111
4,10110+0111--->101100111
检错过程:余数为0,传输过程无误码,余数不为0,传输过程产生误码。
海明码: 2的k次幂-1>=n+K 奇校验和偶校验
做题思路,
1,根据原码确认校验数K,
2,根据K的个数确认每个检验位的位置,插入原数据。
3,生成的总位数位原来数n位+k位
4,每个检验位具体数值为在海明码位置的位数,位置连续组合,空格位置数都参与校验
例子:
传递信息:1010 2^k-1>=k+n n=4--->k=3 所以海明码为(总的为7位,三位检验位插入在2^K-1--->2^0 2^1 2^2 的位置):p1 p2 1 p3 0 1 0
p1(在海明码位置中为第一位,就是本身开始空格一位都参与校验) 所以参与校验的数位:p1 1 0 0 奇校验p1=0 偶校验p1=1
p2(在海明码位置中为第二位,就是两两组合,空格两位都参与校验) 所以参与校验的数位:p2 1 1 0
p3(在海明码位置中为第四位,就是四个组合,空格四位都参与校验)) 所以参与校验的数位:p3 0 1 0
5,存储器的层次结构
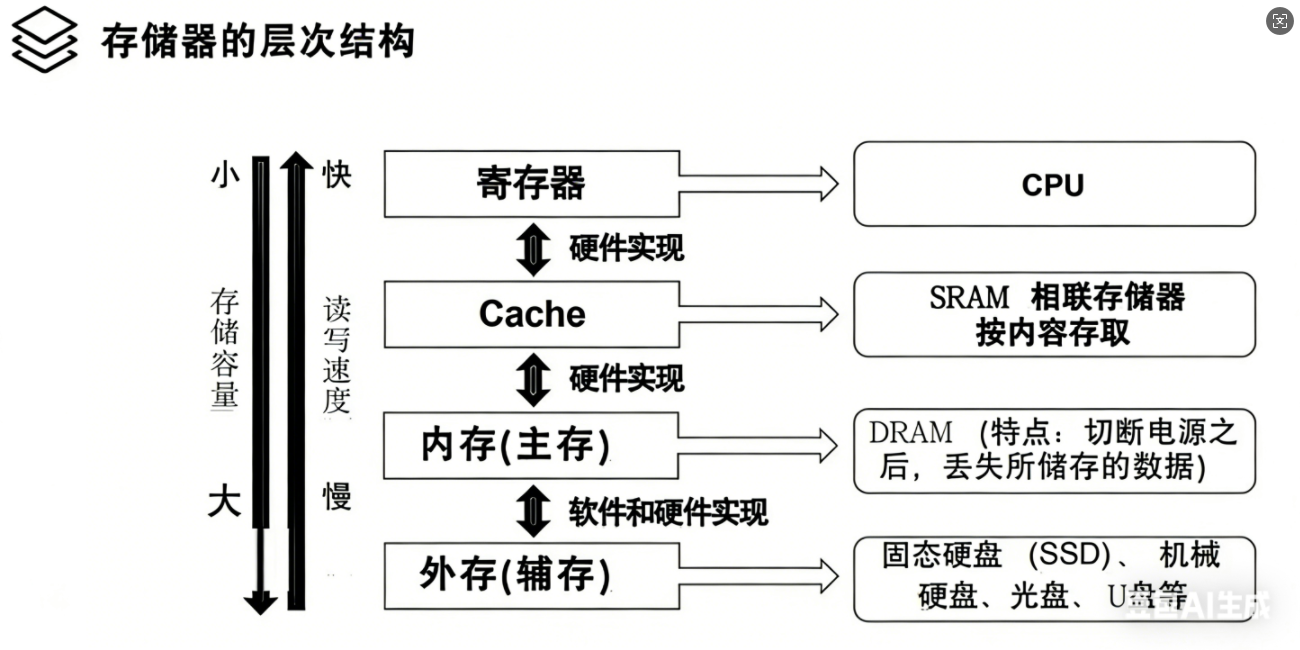
cache位于CPU与主存之间,cache对于程序员来说是透明的。
设置多级高速缓存Cache以提高命中率(访问主存的效率)
使用Cache改善系统性能的依据是程序的局部性原理
时间局部性:被引用过一次的存储器位置在未来会被多次引用,主要体现是主要是循环。
空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用,主要体现是顺序执行的过程。
Cache位于cpu通用寄存器和主存储器之间 (硬件完成地址映射)
CPU读取数据时在cache中命中就不读取内存,不命中就去读取内存
6,cache地址映像方法
存储系统和缓存映射方式:(主存块号---cache地址)
直接映射:对应关系固定,不灵活,会产生浪费
全相联映射:主存块号---cache地址都有映射关系,地址变换复杂,速度慢
组组相联映射:签两种方式组合:先分块再分组
块冲突概率最大:全相联映射<组相联映射<直接映射
访问速度快:全相联映射<组相联映射<直接映射
硬件成本:全相联映射>组相联映射>直接映射
Cache页面淘汰算法包括:
随机替换算法RAND(Random)
先进先出算法FIFO(First in First out)
近期最久未使用算法LRU(Least Recently Used)
最不频繁使用算法 LFU(Least Frequently Used)
优化替换算法
Cache的读写过程:
写直达:同时写Cache与内存,写回:只写Cache,淘汰页面时,写回内存,标记法:只写入内存,并将标志位清零,若用到此数据,只需要再次调取
7,磁盘
机械磁盘存在两组运动:盘的旋转运动,机械臂控制磁头沿半经方向的直线运动
寻道时间:指磁头移动到磁道所需的时间
待时间:等待读写的扇区转到磁头下方所用的时间
存取时间=寻道时间+等待时间
先进行移臂调度,再进行旋转调度。
8,输入输出技术
输入输出设备控制
直接程序控制:程序查询方式:(不间断查询和监听)
程序中断方式:(发出中断,CPU异步)
DMA:(输入输出设备与内存储器直接相连,由DMA控制器控制,不是CPU)占用总线,CPU不能使用总线
通道(IOP):专用处理机
9,Flynn分类法
SISD 单指令单数据流 IBM PC 早期巨型机 冯诺架构
SIMD 单核计算机 GPU
MISD 只有理论
MIMD 当前主流 intel AMD
10,RISC和CISC
RISC 精简指令:指令等长,少,简单 ,硬布线,快。寻址方式少。硬件实现(通用寄存器)X86
CISC 复杂指令:兼容性强,指令多,可变。微程序实现。寻址方式多 ARM
11,流水线
指令:操作码和操作数
微指令由硬件机器执行,虚拟机器执行高级语言
执行过程;取指令--分析--执行
流水线时间计算:
1,流水线周期:时间最长的段为周期。
2,理论公式:流水线执行时间:1条指令执行的总时间+(总指令条数-1)*流水线周期
实践公式:流水线执行时间:流水线周期*指令步数+(总指令条数-1)*流水线周期
3,流水线吞吐率:指令条数/流水线周期
4,流水线加速比:不使用流水线执行时间/使用流水线执行时间
12,冯诺依曼结构和哈弗结构
冯诺依曼结构(普林斯顿结构):程序指令存储器和数据一种并行体系结构,主要特点是将程序和数据存储在存储器合并在一起的存储器结构
一般用于PC处理器,AMD、英特尔的酷睿i3,i5,i7处理器,指令与数据都通过相同的数据总线传输
哈弗结构:程序存储器和数据存储器是两个独立的存储
一般用于嵌入式系统处理器(DSP)数字信号处
四条总线:指令和数据的数据总线与地址总线
13,总线
广义上:
内部总线,芯片级(芯片和处理器)
系统总线(功能分):是板级总线。包括数据总线DB(双向,并行数据传输位数),地址总线AB(单向,系统可管理内存空间的大小)、控制总线CB(传送控制命令)。ISA总线、EISA总线、PCI总线
外部总线:是设备一级的总线,微机和外部设备总线。RS232(串行总线)、SCSI(并行总线)、USB(通用串行,热插拔)
串行总线:单工(单向传输),半双工(同一时间单边传输),全双工(双向,一条发一条收)
使用总线便于增减外设,和减少传输线的条数
14,加密技术和认证技术
常见的对称加密算法:DES、3DES、RC、IDEA、PGP、AES
见的非对称加密算法:RSA、DSA、ECC(椭园曲线算法)等。
信息摘要:MD5、SHA-1、SHA-256
数字签名功能:
报文鉴别:用于证明来源,接收者可以通过签名确定是哪个发送者进行的签名
防止抵赖:防止发送者否认签名,发送者一旦签名,标记就打上了,无法抵赖
防止伪造:防止接收者伪造发送者的签名。
15,计算机可靠性模型
串联系统可靠性:R=R1R2...RN
并联系统 R =1-(1-R1)(1-R2)…(1-RN)

评论交流
欢迎留下你的想法